
Q1:为什么 MySQL 选择使用 B+ 树作为索引结构?
一、 常见数据底层索引结构对比
1. 二叉树类索引(红黑树、AVL 树)
共性:均为自平衡二叉搜索树,查询、插入、删除的时间复杂度均为 O(log**n);
核心差异:
AVL 树:严格高度平衡,任意节点的左右子树高度差绝对值 ≤ 1,树高更接近理想值 log2n;
红黑树:近似平衡,通过节点着色规则保证黑高度平衡,树高最大为 2log2(n+1),树高:红黑树 > AVL 树;
磁盘存储下的致命缺陷:
二叉树的每一层节点对应一次磁盘 IO 操作,执行单条查询时最坏情况需遍历「根节点→叶子节点」的所有层级,树高越高则 IO 次数越多,
磁盘 IO 开销巨大;
适用场景:仅适合内存数据的索引(如 JDK
TreeMap、ConcurrentHashMap),不适合磁盘存储的数据库索引。
2. Hash 索引
核心优势:基于哈希表实现,等值查询时可通过哈希函数快速定位数据,时间复杂度接近 O(1);
核心缺陷:
存在哈希冲突问题(需通过链表 / 红黑树解决冲突,增加额外开销);
不支持范围查询和排序:哈希函数会打乱数据的有序性,无法高效完成
>、<、BETWEEN等范围操作;等值查询性能优异,但无法利用索引完成部分查询优化(如覆盖索引);
适用场景:仅适合等值查询为主的场景(如 Redis 的哈希表),无法满足数据库的复杂查询需求。
3. B 树
结构特点:多路平衡搜索树,非叶子节点和叶子节点均存储数据;
与 B+ 树的核心区别:
二、 数据库为何选择 B+ 树作为主流索引结构
B+ 树的优势完美适配磁盘存储的数据库场景,核心优势如下:
查询性能稳定,IO 开销低B+ 树的非叶子节点仅存储索引键值和子节点指针,不存储数据,因此单个非叶子节点能容纳更多索引条目,树的高度更低(通常 3~4 层即可支撑千万级数据)。无论查询哪个数据,最多只需 3~4 次磁盘 IO,相比二叉树类结构的 IO 次数大幅减少,查询性能稳定。
天然支持范围查询和排序B+ 树的叶子节点通过双向链表有序链接,执行范围查询时,只需定位到范围的起始叶子节点,然后沿链表遍历即可,无需回溯上层节点,效率远高于 B 树和二叉树。
更适合磁盘预读机制磁盘 IO 具有「预读特性」—— 读取数据时会一次性加载相邻的磁盘块到内存。B+ 树的叶子节点按顺序存储,且链表链接,预读机制能大幅提升范围查询的效率;同时非叶子节点的紧凑结构也能减少 IO 次数。
便于实现覆盖索引覆盖索引是指查询的字段全部包含在索引中,无需回表查询。B+ 树的叶子节点存储完整数据(InnoDB 中存储整行数据或主键值),可直接通过索引完成查询,避免回表的额外开销。
三、 面试追问
1. 3 层 B+ 树能存储多少数据?
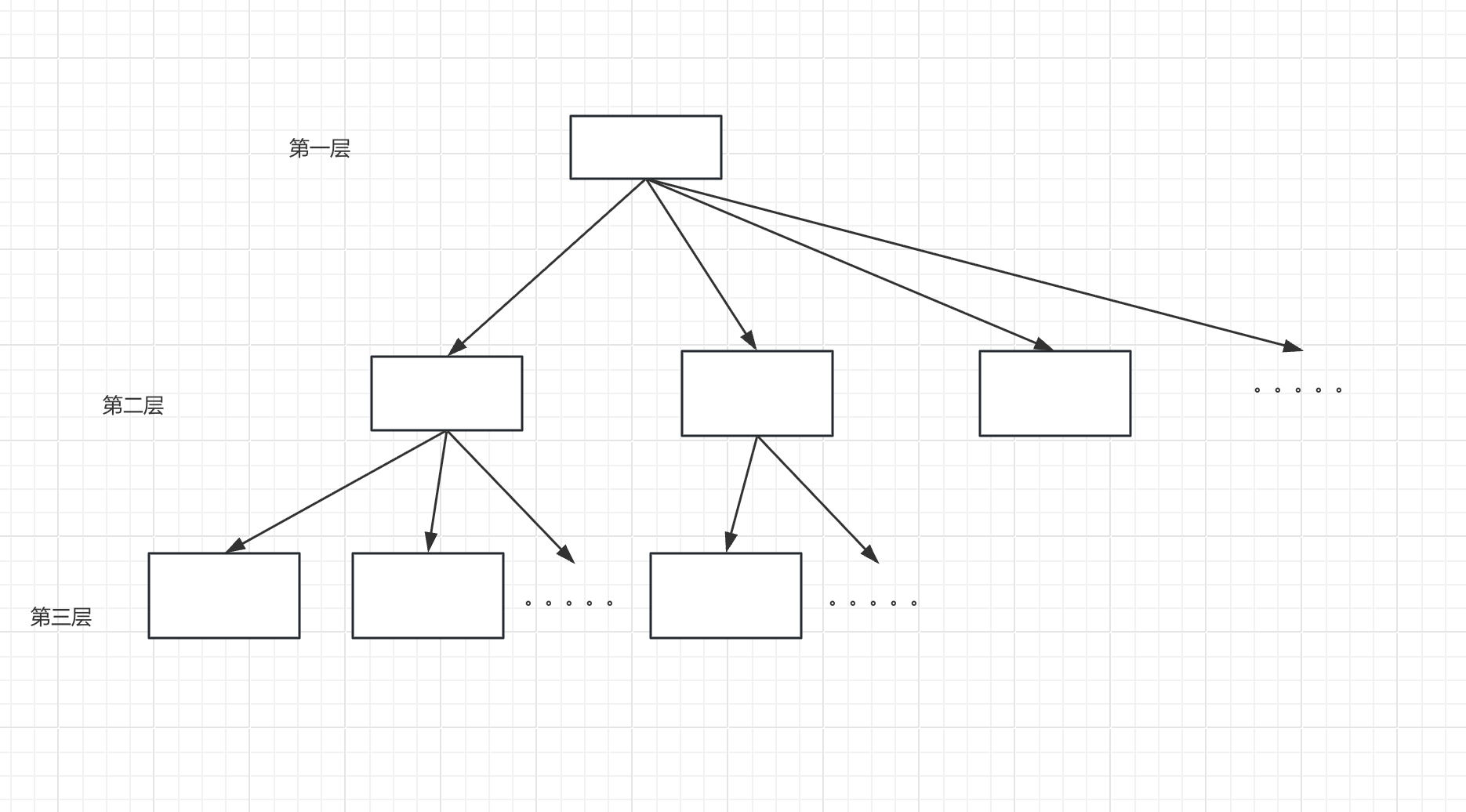
前提条件:
InnoDB 默认页大小:16KB;
索引键类型:
BIGINT(8 字节);页指针大小:6 字节;
叶子节点单条数据行大小:1KB。
计算过程:
根节点(非叶子节点):仅存储「索引键 + 页指针」,单个条目大小 = 8 + 6 = 14 字节;
单页可存储条目数 =16∗1024/14≈1170个,即根节点可指向 1170 个二级节点。
二级节点(非叶子节点):结构与根节点一致,每个二级节点也可存储 1170 个条目;
二级节点总条目数 = 1170∗1170=1368900个,即指向 1368900 个叶子节点。
叶子节点:存储「索引键 + 数据行」,单页可存储数据行数 = 16∗1024/1024=16 条。
3 层 B+ 树总存储数据量 = 1368900∗16=21902400 条(约 2200 万条)。
补充:实际场景中,数据行大小、索引键长度、页内开销(如页头信息)会影响最终存储量,但 3 层 B+ 树支撑千万级数据是行业共识。
2. 为什么 InnoDB 要求主键尽量短?
InnoDB 采用聚簇索引架构,主键的长度直接影响索引的空间效率和查询性能,核心原因如下:
影响主键索引的非叶子节点效率:主键索引的非叶子节点存储「主键值 + 页指针」,主键越短,单个非叶子节点能容纳的条目数越多,树高越低,IO 次数越少;
影响二级索引的空间占用:二级索引的叶子节点存储「二级索引键 + 主键值」,主键越短,二级索引的单个条目体积越小,占用的磁盘空间越少,查询时加载的索引数据也越少。
结论:短主键能降低索引的空间开销,提升索引的查询效率,因此 InnoDB 建议使用自增 INT/BIGINT 作为主键,避免使用长字符串主键。
3. MongoDB 早期用 B 树,后期为何换成 B+ 树?
早期选择 B 树的原因:MongoDB 早期定位为「文档型 NoSQL 数据库」,以单文档的等值查询为主,B 树的非叶子节点存储数据,等值查询时可能无需遍历到叶子节点,能减少一次 IO;
后期换成 B+ 树的核心原因:随着业务发展,范围查询需求大幅增加。B+ 树的叶子节点双向链表天然支持高效范围查询,且排序性能更优;同时 B+ 树的查询性能更稳定,更适合大规模数据的场景。
Q2:MySQL 索引的最左前缀匹配原则是什么?
最左匹配原则是使用联合索引的时候,查询条件会从最左侧的索引开始匹配,然后再是第二列,当第二列没有的时,但是有第三列的时候,若开启了索引下推,则会在引擎层进行条件过滤,减少回表的次数。
索引下推的条件:查询条件需要查询覆盖索引之外的列、索引失效场景(前%查询、函数转换、字符集不匹配等) 索引下推的主要目的是检查回表次数(大量减少io,直接在引擎层使用联合索引的索引当过滤条件)
联合索引(a,b,c),则生成的联合索引树就是先按a排序,a等再按b排,b等再按c排 mysql8.0.13对于联合索引做了优化:skipscan,对于左边的值的数量不多的情况下,当查询没有使用到左边的索引值,只使用右边值的时候,mysql会将查询sql优化成多条等值的sql查询,来使sql走索引查询,extra也就是Using index for skip scan。执行计划也就会将查询的type 变成走range。 skip scan的局限点: 需要使用联合索引,查询不能跨表、查询不能使用group by 和 distinct、查询只能使用一个索引且不能回表、查询条件需要是常量
其实当查询结果被联合索引覆盖的时候,不符合联合索引的查询也会走联合索引,mysql更倾向于扫二级索引拿值,但是这个就不知道是怎么弄的了
拓展:
1.为什么>=不会停止匹配,但是>会停止匹配,因为>=有明确的边界,在条件a=的条件下,后面的bc是有序的,可以进行比较,但是>的情况下,还是通过遍历过滤的 2.在查询条件内a,b联合索引。a =1 and b=1 和 b=1 and a =1 对于优化器来说是一样的 3.索引失效的场景: 1.前模糊查询,破坏了最左前缀,中模糊查询,破坏了连续 2.函数运算/数值运算,String 比较 没有''的字段 3.字符集转换 4.or查询的查询条件没有索引 5.使用select* 6.not exists 7.order by 的字段需要最左匹配,需要添加limit 和where
Q3:MySQL 三层 B+ 树能存多少数据?
前提条件:
InnoDB 默认页大小:16KB;
索引键类型:
BIGINT(8 字节);页指针大小:6 字节;
叶子节点单条数据行大小:1KB。
计算过程:
根节点(非叶子节点):仅存储「索引键 + 页指针」,单个条目大小 = 8 + 6 = 14 字节;
单页可存储条目数 =16∗1024/14≈1170个,即根节点可指向 1170 个二级节点。
二级节点(非叶子节点):结构与根节点一致,每个二级节点也可存储 1170 个条目;
二级节点总条目数 = 1170∗1170=1368900个,即指向 1368900 个叶子节点。
叶子节点:存储「索引键 + 数据行」,单页可存储数据行数 = 16∗1024/1024=16 条。
3 层 B+ 树总存储数据量 = 1368900∗16=21902400 条(约 2200 万条)。
补充:实际场景中,数据行大小、索引键长度、页内开销(如页头信息)会影响最终存储量,但 3 层 B+ 树支撑千万级数据是行业共识。 innodb_page_size可以调整页面的大小,4kb 8kb 16kb 32kb 64kb,页越大,扇出越大,树越矮。但是页越大的缺点就是:内存利用率不够空间浪费,恢复慢,查询定位慢、不可动态修改,初始化好后修改得重新建表