
一、 MySQL B+ 树查询数据全过程
MySQL 的 InnoDB 引擎默认使用 B+ 树作为索引结构,数据查询的核心流程分为「垂直定位」和「页内查找」两个阶段,其中 B+ 树的每个节点对应一个 16KB 大小的数据页,根节点数据页常驻内存,是查询高效的基础。
(一) 垂直定位:从根节点到叶子节点的层层导航
垂直定位的核心目的是通过 B+ 树的非叶子节点,快速缩小查询范围,最终定位到存储完整数据的叶子节点数据页,具体流程如下:
起始点:从根节点数据页开始(常驻内存,无需额外磁盘 I/O),根节点属于非叶子节点,仅存储「索引关键字(分界值)」和「子节点指针」(指向子节点数据页的磁盘地址),不存储完整数据记录。
核心操作:将查询条件(如主键
id=15)与根节点页内的索引关键字进行二分查找(非叶子节点内的索引关键字按升序有序排列,支持高效二分查找)。层级导航:根据二分查找结果,确定对应的子节点指针,发起磁盘 I/O 加载对应的子节点数据页(可能是中间非叶子节点,也可能是叶子节点)到内存。
终止条件:重复上述 “二分查找 + 加载子节点” 的步骤,遍历中间非叶子节点(B+ 树高度通常为 3-4 层,磁盘 I/O 次数极少),直到成功加载到目标叶子节点数据页,垂直定位阶段结束。
(二) 页内查找:叶子节点数据页内的精准定位
叶子节点数据页存储完整的数据记录(聚簇索引)或主键指针(二级索引),页内查找的核心是通过「页目录」优化查找效率,避免全页单链表遍历,具体流程如下:
前置准备:加载目标叶子节点数据页到内存后,先解析数据页的完整结构,关键组成部分如下:
核心步骤:
步骤 1:对页目录(slot)进行二分查找,快速定位到目标记录所在的分组(页目录按组有序排列,支持随机访问,二分查找效率最优)。
步骤 2:进入目标分组后,顺着单链表遍历组内记录(组内记录数量极少,遍历开销可忽略),找到与查询条件完全匹配的记录。
步骤 3:若为聚簇索引(主键索引),直接返回该记录的完整行数据;若为二级索引,需获取主键值,再通过聚簇索引进行 “回表查询”,最终返回完整数据。
(三) 完整查询流程总结
根节点数据页二分查找 → 定位中间非叶子节点 → 中间节点二分查找 → 定位叶子节点数据页 → 叶子节点页目录二分查找 → 分组内单链表遍历 → 找到目标记录(如需回表则补充回表流程)→ 返回查询结果。
二、 MySQL 中 count (*)、count (1) 和 count (字段名) 的区别
count() 函数是 MySQL 中用于统计记录行数的聚合函数,三种常见写法的核心差异体现在统计范围、底层实现和执行效率上,且在 InnoDB 和 MyISAM 引擎下表现存在差异。
(一) 核心区别整理
1、count (*) 与 count (1)(InnoDB 引擎)
统计结果:完全一致,均统计满足
WHERE条件的所有行数量,不忽略NULL值行。底层实现:MySQL 优化器会将二者优化为相同执行逻辑,均不读取任何实际业务字段值。其中
count(*)是 SQL 标准中的统计行数语法,InnoDB 会优先选择占用空间最小的二级索引(而非聚簇索引)进行遍历统计,减少磁盘 I/O;count(1)是用常量1填充每行后统计行数,优化后与count(*)效率几乎无差异。执行效率:效率较高(无额外判断逻辑,优先使用小索引),是统计总行数的最优选择。
2、count (字段名)
统计结果:仅统计满足
WHERE条件且该字段值为非NULL的行数量,会忽略字段值为NULL的行。底层实现:必须读取该字段的实际值,逐一判断是否为
NULL,再进行计数。若该字段未建立索引,会触发全表扫描;若建立索引,可通过索引遍历统计,但效率仍低于count(*)/count(1)。执行效率:效率较低(存在
NULL判断逻辑,需读取字段值),且字段类型越大、索引越大,效率越低。
MyISAM 引擎的特殊表现
MyISAM 引擎会在表结构中存储表的总行数(无
WHERE条件时),此时count(*)无需遍历索引,直接返回存储的总行数,效率极高。当存在
WHERE条件时,MyISAM 引擎的统计逻辑与 InnoDB 一致,需遍历满足条件的记录。
大表统计辅助方案
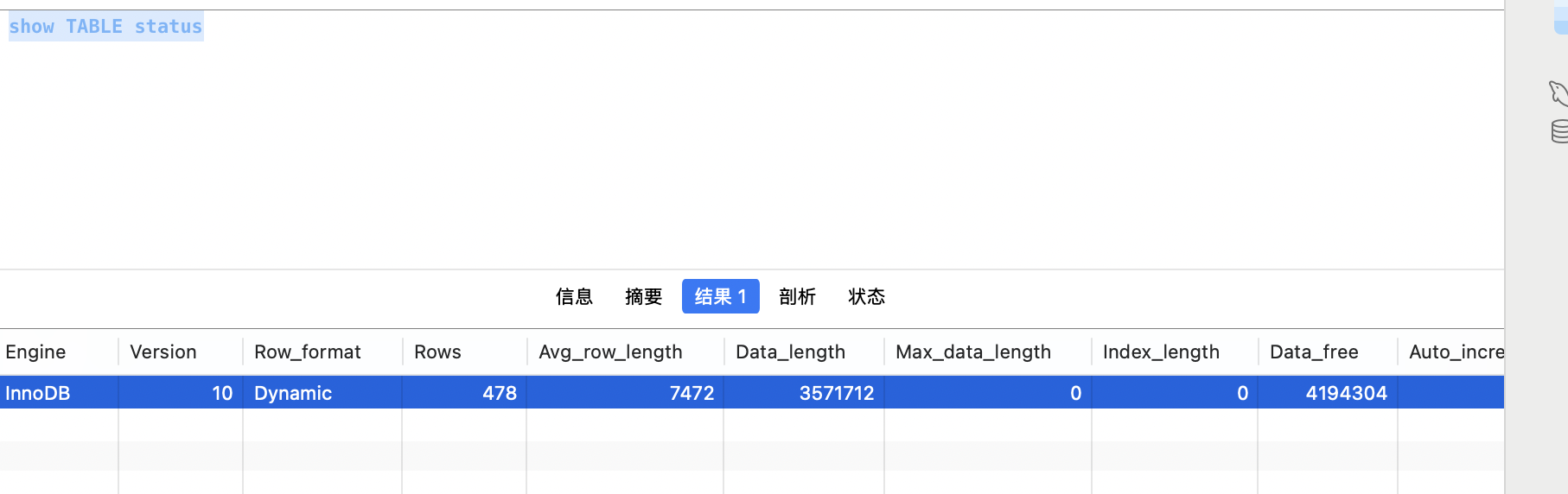
对于千万级以上大表,使用
count(*)统计总行数会消耗大量时间,可使用SHOW TABLE STATUS;命令粗略查询数据量(该命令返回的Rows字段为估算值,误差通常在 5%-10% 左右,适用于无需精准统计的场景)。
(二) 核心使用建议
统计满足条件的总行数:优先使用
count(*)(语义清晰,优化最优,兼容性最好)。统计某字段非空值的行数:只能使用
count(字段名),且尽量给该字段建立索引提升效率。避免使用
count(主键):主键是聚簇索引,占用空间大,统计效率低于count(*),且语义与count(*)一致,无额外价值。
三、 MySQL 中 varchar 和 char 的区别
varchar 和 char 是 MySQL 中两种常用的字符串类型,核心差异在于「长度特性」和「存储方式」,进而影响性能和适用场景。
(一) 核心区别整理
char (n):固定长度字符串
长度特性:
n表示固定字符数(默认配置下),最大取值为 255。存储空间:无论实际存储的数据长度是否达到
n,均占用n个字符的固定空间,不足n时末尾用空格填充。末尾空格处理:存储时自动填充空格至指定长度,查询时自动截断末尾所有空格(遵循 SQL 标准),可能导致业务逻辑异常(如无法区分存储的 “abc” 和 “abc ”)。
性能表现:存储紧凑,无需解析长度标识,查询、排序效率较高,无行溢出风险。
适用场景:数据长度固定且较短的场景,如性别(男 / 女)、手机号(11 位)、MD5 值(32 位)、邮编等。
varchar (n):可变长度字符串
长度特性:
n表示最大字符数(默认配置下),最大取值受限于 65535 字节(实际可用小于该值,受编码、行总长度限制)。存储空间:实际存储数据长度 + 1-2 个字节的「长度标识」+ 可选 1 个字节的「NULL 标识」(当字段允许
NULL时)。其中长度标识的选择规则:实际存储长度 ≤ 255 字节时用 1 个字节,> 255 字节时用 2 个字节。末尾空格处理:存储时保留末尾空格,查询时也保留末尾空格,无自动截断逻辑。
性能表现:
需先解析长度标识才能获取实际数据,效率略低于
char;当字段长度超过 768 字节时,会触发「行溢出」:前 768 字节存储在原数据行内,超出部分存储在独立的「溢出页」中,原行仅保留 20 字节指针指向溢出页,查询时需额外访问溢出页,增加磁盘 I/O;
大长度
varchar排序时,若sort_buffer_size不足以容纳排序数据,会触发「双路磁盘排序」,大幅降低排序效率。
适用场景:数据长度波动较大的场景,如用户名(4-20 位)、商品标题(10-100 位)等。
大文本数据替代方案
对于超过 varchar 存储上限或长度极大的文本数据(如文章内容、商品详情),不推荐使用大长度
varchar,优先使用 text、longtext类型,且建议单独拆分表存储,避免影响其他字段的查询效率。
(二) 核心使用建议
优先根据数据长度是否固定选择类型,定长选
char,变长选varchar。避免使用
char(n)存储需要保留末尾空格的数据,防止查询时空格被截断导致业务异常。避免给
varchar设置过大的n(如varchar(65535)),即使实际使用长度短,也可能占用更多内存(如排序时sort_buffer预留对应空间)。