
MySQL 中如何解决深度分页的问题?
1. 深度分页的定义与痛点
深度分页指 LIMIT 大偏移量, 小条数 形式的查询(如 LIMIT 999999, 10),核心痛点是:
MySQL 会先扫描偏移量前的所有数据(如 999999 条),再丢弃这些数据,仅返回目标条数;
大量无效 IO 消耗,偏移量越大,查询效率越低。
2. 核心优化思路
避免「全量扫描 + 全量排序 + 海量跳过」,改为「精准定位起始位置→按需取数」,核心是利用索引降低无效操作成本。
3. 具体解决方案
(1)子查询 / 联表优化(最常用)
适用场景:有唯一有序字段(如自增 ID)、需定位到指定页码的场景。
原始查询(低效):
SELECT * FROM table WHERE name = "demo" ORDER BY id LIMIT 999999, 10;执行逻辑:走
name二级索引→筛选出所有name="demo"的 ID→对 ID 做filesort(文件排序)→跳过 999999 条 ID→回表取 10 条全字段,核心瓶颈是「百万级 ID 排序」。优化查询(子查询版):
SELECT * FROM table WHERE name = "demo" AND id >= ( SELECT id FROM table WHERE name = "demo" ORDER BY id LIMIT 999999, 1 ) ORDER BY id LIMIT 10;执行逻辑:
① 子查询:走
name二级索引(覆盖索引,仅含name+ID)→无需排序,直接遍历到第 999999 条取起始 ID(锚点);② 外层查询:用
id>=起始ID精准筛选→借助主键索引有序性排序(低成本)→仅回表取 10 条数据。优化查询(联表版)
SELECT * FROM table INNER JOIN ( SELECT id FROM table WHERE name = 'demo' ORDER BY id LIMIT 999999, 10 ) AS t ON table.id = t.id;逻辑与子查询一致,仅语法形式不同,需保证
name有二级索引。
核心优势:保留「定位到指定页码」的能力,性能比原始查询提升 10~100 倍;
注意事项:需依赖唯一有序字段(如 ID),若排序字段为非 ID(如 create_time),需建 (name, create_time) 联合索引,子查询取 create_time 作为锚点。
(2)游标分页
适用场景:仅需连续翻页(如 “下一页”)、无需跳转到指定页码的场景。
实现逻辑:每次查询取上一页的最大 ID 作为条件,避免偏移量:
-- 第一页 SELECT * FROM table WHERE name = "demo" ORDER BY id LIMIT 10; -- 第二页(假设上一页最大 ID 为 10) SELECT * FROM table WHERE name = "demo" AND id > 10 ORDER BY id LIMIT 10;
核心优势:无偏移量,全程走索引,效率无衰减;
缺点:
① 仅支持连续翻页,无法直接定位到指定页码;
② 依赖唯一有序字段(如 ID);
③ 删除数据可能导致页面数据错乱(可通过 ID+更新时间戳 做复合游标规避)。
(3)搜索引擎优化
适用场景:海量数据(千万级以上)、无唯一有序字段、需复杂排序 / 筛选的场景。
实现逻辑:将 MySQL 数据同步到 Elasticsearch(ES),利用 ES 的
search_after特性实现深度分页:// ES 示例:用上一页最后一条的 sort 值作为游标 SearchRequest request = new SearchRequest("table_index"); SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); sourceBuilder.query(QueryBuilders.termQuery("name", "demo")); sourceBuilder.sort("id", SortOrder.ASC); sourceBuilder.searchAfter(new Object[]{上一页最大ID}); // 替代偏移量 sourceBuilder.size(10); request.source(sourceBuilder);
核心优势:支持海量数据、复杂排序 / 筛选,无深度分页性能衰减;
注意事项:需保证 MySQL 与 ES 数据同步的一致性(如通过 binlog 同步工具)。
什么是 MySQL 的主从同步机制?它是如何实现的?
1. 核心原理
主从同步的核心是「二进制日志(binlog)的复制与重放」,将主库的事务操作同步到从库,实现数据一致性。
2. 完整同步流程
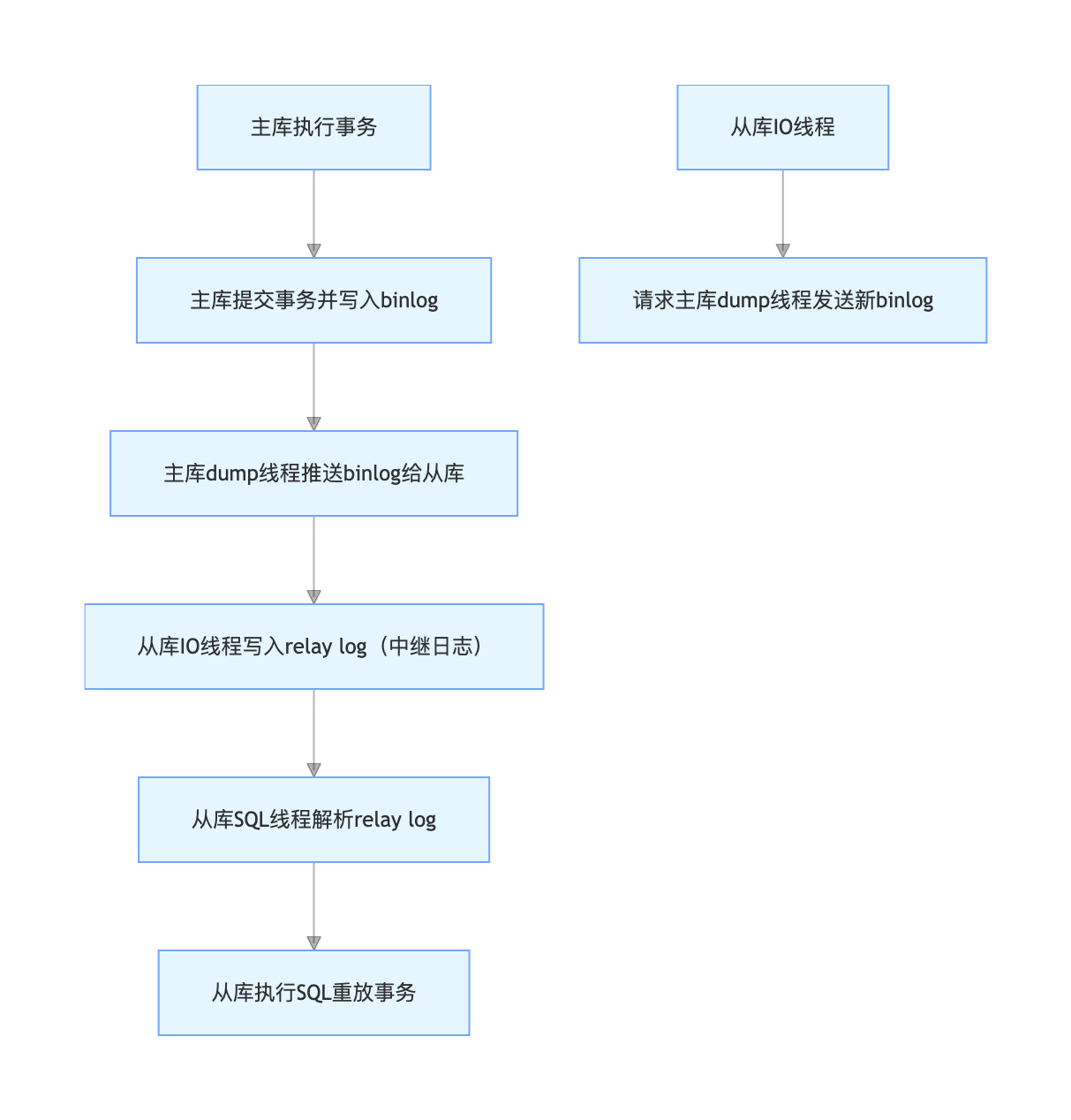
关键说明:
binlog:主库记录所有数据修改操作的日志,是同步的数据源;relay log:从库本地存储的主库 binlog 副本,避免直接读取主库 binlog 导致性能损耗;dump线程:主库专门用于给从库推送 binlog 的线程;IO线程:从库负责拉取 binlog 的线程;SQL线程:从库负责解析 relay log 并执行的线程。
3. 同步方式(按主库响应时机划分)
半同步复制关键配置(MySQL 5.7+):
-- 开启半同步复制
SET GLOBAL rpl_semi_sync_master_enabled = ON;
SET GLOBAL rpl_semi_sync_slave_enabled = ON;
-- 推荐配置:主库先同步binlog再提交事务(避免主从不一致)
SET GLOBAL rpl_semi_sync_master_wait_point = 'AFTER_SYNC';4. 并行复制演化(解决从库 SQL 线程单线程瓶颈)
8.0 并行复制配置:
SET GLOBAL slave_parallel_type = 'WRITESET';
SET GLOBAL slave_parallel_workers = 8; -- 一般设为 CPU 核心数的 2 倍三、MySQL 主从同步延迟问题处理
1. 主从延迟的定义与常见原因
定义:从库数据落后于主库的时间差(可通过
Seconds_Behind_Master查看);核心原因:
① 硬件:从库配置低于主库、从库查询业务抢占同步资源;
② 配置:未开启并行复制、binlog/relay log 配置不合理;
③ 业务:主库大事务(如批量插入 / 更新)、从库慢查询;
④ 网络:主从跨机房 / 跨地域导致 binlog 传输延迟;
⑤ 架构:SQL 线程单线程瓶颈(5.6 前无并行复制)。
2. 延迟处理方案(从易到难)
(1)查询层面优化
关键实时查询走主库:如订单支付、用户登录等核心场景,直接查询主库;
延迟感知路由:记录数据插入时间戳,短时间内(如 5 秒)的查询走主库,超过则走从库;
兜底查询:从库查不到的数据自动降级查主库(如用户最新订单)。
(2)配置层面优化
开启并行复制(5.7+/8.0+):参考上文并行复制配置;
优化 binlog 格式:主库使用
ROW格式(精准同步),并开启binlog_row_image = MINIMAL(仅记录修改列,减少日志体积);调整半同步参数:延长主库等待从库确认的超时时间(避免频繁切回异步):
SET GLOBAL rpl_semi_sync_master_timeout = 10000; -- 10秒超时
(3)硬件 / 部署层面优化
从库配置不低于主库:CPU / 内存 / 磁盘 IO 需匹配主库,推荐 SSD 磁盘;
拆分从库角色:单独部署「同步从库」(仅做数据同步)和「查询从库」(处理业务查询),避免查询抢占同步资源;
就近部署:主从尽量同机房,跨地域场景可搭建多级从库(主→区域从→本地从)。
(4)架构层面优化
引入中间件:如 MyCat、ShardingSphere,自动路由实时查询到主库、非实时查询到从库;
缓存兜底:写主库时同步更新 Redis 缓存,查询优先读缓存,降低数据库查询压力;
多从库负载均衡:部署多个从库,分摊查询压力,避免单从库过载导致同步延迟。
3. 延迟监控
-- 查看从库延迟(单位:秒)
SHOW SLAVE STATUS\G; -- 关注 Seconds_Behind_Master 字段
-- 查看并行复制状态(8.0+)
SHOW PROCESSLIST; -- 查看 SQL 线程/IO 线程状态
SHOW GLOBAL STATUS LIKE 'Slave_%'; -- 查看并行复制工作线程状态